
티스토리 뷰
캐시는 프로세서와 메모리 사이의 속도 차이를 해결하기 위해 사용되는 작고 빠른 메모리입니다. 주로 프로세서가 빠른 반응 속도를 위해 자주 사용하는 데이터를 캐시에 저장하여 전체 시스템 속도를 높입니다. 캐시는 지역성 원리(Principle of Locality)를 따르며, 시간 지역성(Temporal locality)과 공간 지역성(Spatial locality)으로 구분됩니다.

지역성 원리를 이해하기 위해 구체적인 예시를 들어볼게요!
예를 들어, 컴퓨터에서 어떤 프로그램을 실행한다고 가정해 봅시다. 이 프로그램은 배열(Array)에 저장된 데이터를 반복적으로 읽고 쓰는 작업을 수행합니다. 배열의 크기는 1,000,000이고, 프로그램은 다음과 같은 순서로 데이터에 접근합니다.
1. 0번 인덱스부터 999,999번 인덱스까지 순차적으로 접근합니다.
2. 999,999번 인덱스부터 0번 인덱스까지 역순으로 접근합니다.
3. 0번 인덱스부터 999,999번 인덱스까지 순차적으로 접근합니다.
C++코드와 JavaScript 코드로 예시를 구현해볼게요.
C++
#include <iostream>
int main() {
const int SIZE = 1000000;
int* array = new int[SIZE];
// 0번 인덱스부터 999,999번 인덱스까지 순차적으로 접근
for (int i = 0; i < SIZE; ++i) {
array[i] = i;
}
// 999,999번 인덱스부터 0번 인덱스까지 역순으로 접근
for (int i = SIZE - 1; i >= 0; --i) {
array[i] = i;
}
// 0번 인덱스부터 999,999번 인덱스까지 순차적으로 접근
for (int i = 0; i < SIZE; ++i) {
array[i] = i;
}
delete[] array;
return 0;
}
JavaScript
const SIZE = 1000000;
let array = new Array(SIZE);
// 0번 인덱스부터 999,999번 인덱스까지 순차적으로 접근
for (let i = 0; i < SIZE; i++) {
array[i] = i;
}
// 999,999번 인덱스부터 0번 인덱스까지 역순으로 접근
for (let i = SIZE - 1; i >= 0; i--) {
array[i] = i;
}
// 0번 인덱스부터 999,999번 인덱스까지 순차적으로 접근
for (let i = 0; i < SIZE; i++) {
array[i] = i;
}
C++ 코드를 사용하는 이유는 캐시와 메모리 관리에 대한 이해를 돕기 위해서입니다. C++은 메모리를 직접 관리할 수 있는 대표적인 언어로, 메모리 할당 및 해제에 대한 예제를 쉽게 작성할 수 있습니다. 또한, C++의 컴파일러 최적화를 통해 메모리 접근 및 캐시 동작에 대한 예측이 더 정확해집니다.
반면 JavaScript는 메모리 관리를 직접 제어할 수 없는 언어입니다. 이는 자바스크립트의 가비지 컬렉션(Garbage Collection) 메커니즘이 메모리를 자동으로 관리하기 때문입니다. 이로 인해 캐시와 메모리 관리에 대한 예제를 작성할 때, C++ 보다 JavaScript가 상대적으로 제한적일 수 있습니다.
하지만, 위에서 제시한 JavaScript 예제도 시간 지역성과 공간 지역성에 대한 이해를 돕는데 충분하다고 생각했고 프론트엔드 개발자를 위한 포스팅이라 C++, JavaScript 둘 다 준비해 봤습니다.
위 프로그램의 경우, 배열의 크기가 1,000,000인 정수 배열을 생성하고, 순차적 접근과 역순 접근을 반복하여 데이터에 접근합니다. 이 예시에서 시간 지역성과 공간 지역성 원리가 적용됩니다.
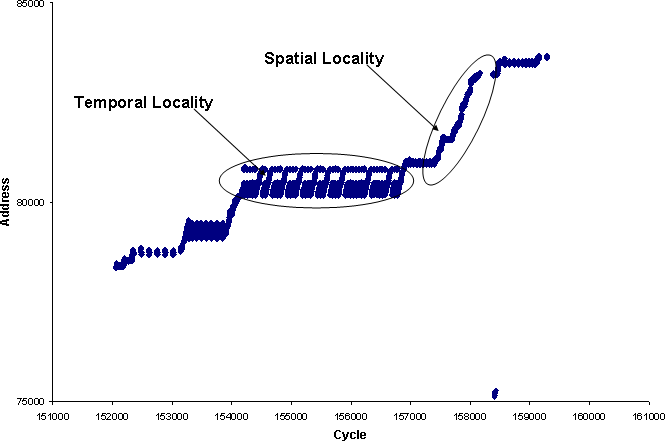
시간 지역성(Temporal Locality)의 경우, 각 인덱스에 저장된 데이터는 한 번 접근하면 가까운 미래에 다시 접근되기 때문에 캐시에 저장되어 있으면 접근 시간이 단축됩니다. 따라서, 최근에 참조된 데이터가 캐시에 저장되어 있으면 이 프로그램의 성능이 향상됩니다.
공간 지역성(Spatial Locality)은 인접한 메모리 위치에 저장된 데이터가 함께 사용될 가능성이 높다는 원리입니다. 이 예시에서는 배열의 데이터가 순차적으로 접근되므로 인접한 메모리 위치에 있는 데이터를 미리 캐시에 저장해 두어 접근 시간을 줄일 수 있습니다. 이를 통해 프로그램의 성능이 향상됩니다.
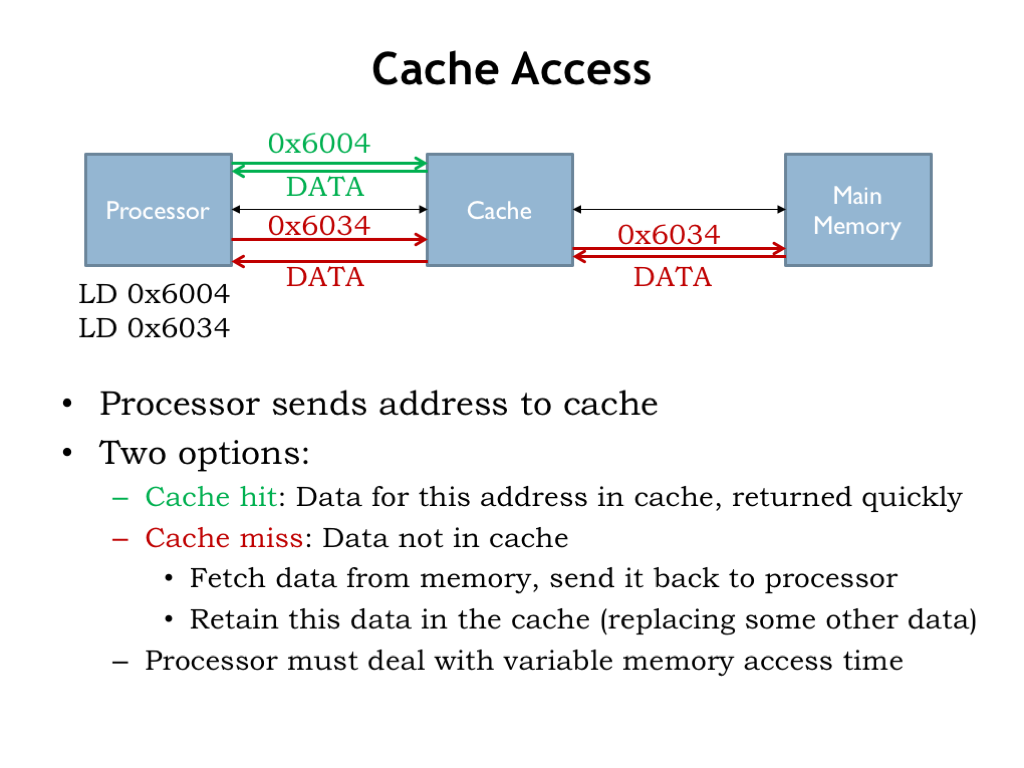
캐시 알고리즘
여러 가지 캐시 알고리즘이 있어요. 이번 포스팅에서는 간단하게 소개하고 넘어가려고 합니다.
최근 최소 사용(LRU, Least Recently Used): 이 알고리즘은 최근에 사용하지 않은 데이터를 캐시에서 교체하는 방식으로 작동합니다. 시간 지역성을 고려하여 구현되며, 최근에 사용한 데이터가 곧 다시 사용될 가능성이 높다는 점을 활용합니다.
최적(OPT, Optimal): 이 알고리즘은 미래에 가장 오랫동안 사용되지 않을 데이터를 캐시에서 교체하는 방식으로 작동합니다. 이 알고리즘은 이론적으로 최적의 캐시 효율을 제공하지만, 실제 구현에서 미래의 메모리 참조를 미리 알기 어렵기 때문에 실용적이지 않습니다.
응용 프로그램 특정(Application-Specific): 캐시 교체 정책이 애플리케이션의 특성에 따라 결정됩니다. 이 알고리즘은 공간 지역성 원리를 활용하며, 애플리케이션에서 인접한 메모리 위치에 대한 접근이 높은 경우 효과적입니다.
적응형(Adaptive): 적응형 캐시 알고리즘은 시간 지역성과 공간 지역성의 패턴을 동적으로 학습하고 적용하여 캐시 성능을 최적화합니다. 이 알고리즘은 프로그램의 실행 동안 메모리 접근 패턴을 모니터링하고, 해당 패턴에 기반하여 캐시 정책을 조정합니다.
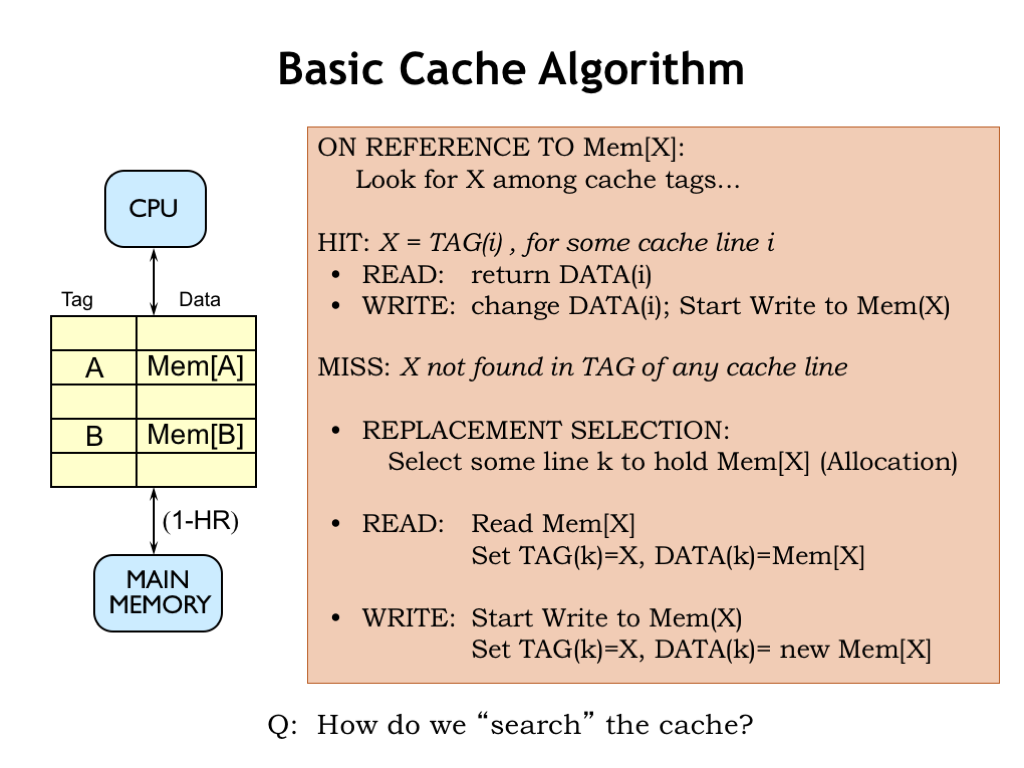
지금까지 기본적으로 캐시를 이해하기 위해 지역성 원리(Principle of Locality)를 구체적인 예시를 통해 알아보았고 캐시 알고리즘도 맛보기로 보았습니다. 이제 캐시에는 어떠한 유형들이 있는지 알아보려고 합니다.
다양한 캐시 유형
- L1 캐시 (Level 1 Cache): 프로세서와 가장 가까운 캐시로, 속도를 위해 Instruction Cache와 Data Cache로 나뉜다.
- L2 캐시 (Level 2 Cache): 용량이 큰 캐시로, 프로세서와 더 멀리 떨어져 있다.
- L3 캐시 (Level 3 Cache): 멀티 코어 시스템에서 여러 코어가 공유하는 캐시로, L2 캐시보다 더 크다.
- 하드웨어 캐시 (Hardware Cache): 하드웨어 구성 요소에 의해 관리되는 캐시로, CPU와 GPU에 사용된다.
- 브라우저 캐시 (Browser Cache): 웹 브라우저에서 사용되는 캐시로, 웹 페이지의 요소를 저장하여 빠르게 불러온다.
- 분산 캐시 (Distributed Cache): 여러 시스템 간에 데이터를 저장하고 공유하기 위해 사용되는 캐시이다.
- 콘텐츠 전송 네트워크 (CDN) 캐시: CDN에서 사용되는 캐시로, 사용자에게 가까운 서버에서 웹 콘텐츠를 전송한다.
- 메모리 캐시 (Memory Cache): RAM에 저장되는 캐시로, 데이터베이스 조회 결과 등을 저장한다.
- 트랜잭션 캐시 (Transactional Cache): 데이터베이스 트랜잭션을 처리하는 동안 일시적으로 데이터를 저장하는 캐시이다.
- 서비스 워커 캐시 (Service Worker Cache): 웹 애플리케이션에서 오프라인 기능을 지원하기 위해 사용되는 캐시이다.
Cache를 $로도 표현하기도 해요. 캐시(Cache)의 발음이 현금을 뜻하는 'Cash’와 같기 때문이에요.
프론트엔드 개발자가 주로 사용하는 캐시 유형
프론트엔드 개발자가 주로 사용하는 캐시 유형은 다음과 같아요.
- 브라우저 캐시
- 콘텐츠 전송 네트워크 (CDN) 캐시
- 메모리 캐시
- 서비스 워커 캐시
브라우저 캐시
브라우저 캐시는 웹 페이지의 요소를 저장하여 빠르게 불러옵니다. 예를 들어, 웹 페이지에 사용되는 이미지를 브라우저 캐시에 저장해 두면, 다음 방문 시 이미지를 더 빠르게 불러올 수 있습니다.
<!-- HTML 코드 예시 -->
<meta http-equiv="Cache-Control" content="max-age=86400" />
콘텐츠 전송 네트워크 (CDN) 캐시
CDN 캐시는 사용자에게 가까운 서버에서 웹 콘텐츠를 전송합니다. 이를 통해 웹 페이지의 로딩 시간을 줄일 수 있습니다.
메모리 캐시
메모리 캐시는 RAM에 저장되며, 데이터베이스 조회 결과 등을 저장한다. 이를 통해 데이터베이스에 빈번한 요청을 줄이고 애플리케이션의 성능을 향상시킬 수 있습니다.
// JavaScript 코드 예시
const cache = new Map();
function getData(key) {
if (cache.has(key)) {
return cache.get(key);
}
const data = fetchDataFromDatabase(key);
cache.set(key, data);
return data;
}
서비스 워커 캐시
서비스 워커 캐시는 웹 애플리케이션에서 오프라인 기능을 지원하기 위해 사용됩니다. 이를 통해 네트워크 연결이 끊겼을 때에도 애플리케이션을 계속 사용할 수 있습니다.
프론트엔드에서 캐시를 잘 활용하기 위한 전략
지금부터는 작성자가 학습하고 느낀 부분을 서술할 예정입니다. 따라서 지극히 주관적이며 사실과 다른 부분이 있을 수 있습니다. 틀린 부분이 있다면 댓글을 통해 알려주시면 감사하겠습니다.
크게 4가지로 생각해 봤습니다.
캐시 유효 기간을 설정하자
캐시의 유효 기간을 적절하게 설정하여, 캐시 된 데이터가 오래된 경우 새로운 데이터로 갱신되도록 합니다. 이를 통해 최신 정보를 유지하면서 성능 향상을 도모할 수 있다고 생각합니다.
불필요한 캐시를 회피하자
동적 데이터나 자주 변경되는 데이터는 캐시 하지 않는 것이 좋습니다. 이를 통해 항상 최신 정보를 보장하고 캐시 공간을 효율적으로 사용할 수 있습니다.
캐시 우선순위를 결정하자
데이터의 중요도와 사용 빈도에 따라 캐시 우선 순위를 결정합니다. 이를 통해 중요한 데이터를 빠르게 불러올 수 있도록 합니다.
-> 더 나아가 우선 순위를 결정할 때 빈도에만 따라서해도 될까라는 고찰
캐시 성능도 고려하면 좋겠다고 생각했습니다. 캐시 성능을 측정하는 데 사용되는 주요 메트릭들은 다음과 같았어요.

캐시 히트율(Cache Hit Rate): 캐시 히트율은 캐시에서 원하는 데이터를 찾았을 때의 비율을 나타냅니다. 캐시 히트율이 높을수록 성능이 좋다고 판단할 수 있습니다. 캐시 히트율은 다음과 같이 계산할 수 있습니다.
캐시 히트율 = (캐시 히트 수 / (캐시 히트 수 + 캐시 미스 수)) * 100
캐시 미스율(Cache Miss Rate): 캐시 미스율은 캐시에서 원하는 데이터를 찾지 못했을 때의 비율을 나타냅니다. 캐시 미스율이 낮을수록 성능이 좋다고 판단할 수 있습니다. 캐시 미스율은 다음과 같이 계산할 수 있습니다.
캐시 미스율 = (캐시 미스 수 / (캐시 히트 수 + 캐시 미스 수)) * 100
평균 메모리 액세스 시간(Average Memory Access Time, AMAT): 평균 메모리 액세스 시간은 캐시와 메인 메모리의 액세스 시간을 고려하여 계산합니다. 캐시 히트 시간과 캐시 미스 패널티를 사용하여 AMAT를 계산할 수 있습니다.
평균 메모리 액세스 시간 = 캐시 히트 시간 + (캐시 미스율 * 캐시 미스 패널티)
캐시 파티셔닝 :: 캐시를 개인화하자
사용자별로 다른 캐시를 구성하여 개인화된 사용자 경험을 제공합니다. 이를 통해 각 사용자에게 최적화된 콘텐츠를 제공할 수 있습니다.
캐시를 이용하면 무조건 좋나요????? 그렇다고 캐시를 무분별하게 사용해서는 안 됩니다. 캐시 활용 시 주의하면서 사용해야 해요!!
캐시 활용 시 주의사항
데이터 일관성 유지:
캐시 된 데이터와 원본 데이터 간의 일관성을 유지해야 합니다. 데이터 변경 시 캐시도 함께 갱신되도록 주의합니다.
보안 고려:
캐시된 데이터는 보안상의 이유로 다른 사용자에게 노출되지 않아야 합니다. 암호화 및 인증 기능을 사용하여 캐시 데이터의 보안을 강화합니다.
캐시 용량 관리:
캐시 용량이 고갈되지 않도록 주기적으로 캐시를 정리하고 관리합니다. 이를 통해 캐시의 효율성을 유지할 수 있습니다.
글 마무리를 하자면 캐시는 컴퓨터 시스템의 성능을 향상시키는 중요한 기술입니다. 우리가 사용하는 거의 모든 것에는 캐시가 있죠!! 프론트엔드 개발에서도 다양한 캐시 유형과 전략을 활용하여 애플리케이션의 로딩 속도를 높이고 사용자 경험을 향상시킬 수 있습니다. 캐시 활용 시 주의사항을 지켜 데이터의 일관성과 보안을 유지하면서 캐시의 장점을 최대한 활용하도록 노력해야 한다고 생각합니다.
좋아요는 로그인하지 않아도 누를 수 있습니다!
참고
https://computationstructures.org/lectures/caches/caches.html
https://stackoverflow.com/questions/7638932/what-is-locality-of-reference
'FRONT-END' 카테고리의 다른 글
| 프론트엔드 이미지 최적화: 압축, 변환을 활용한 효율적인 이미지 관리 (8) | 2023.05.05 |
|---|---|
| FOUC와 FOUT 현상 극복하기: 브라우저 렌더링 원리와 최적화 전략 (6) | 2023.04.29 |
| Vercel, 그냥 사용하시나요? (feat. SaaS가 해결해주는 문제) (5) | 2023.04.12 |
| [React] map 함수 사용 시 Key 값을 부여해 주는 이유 (2) | 2022.04.26 |
| [React] .env (환경변수 관리) (4) | 2022.03.17 |
- Total
- Today
- Yesterday
- 정리
- OS
- C++
- 구현
- 알고리즘
- BFS
- 프로그래머스
- 자바
- 쉽게배우는
- Web
- 파이썬
- 쉽게배우는자바프로그래밍
- 해답
- CPP
- 자바스크립트
- 정답
- JS
- 풀이
- 문자열
- 쉽게 배우는 자바 프로그래밍
- py
- 그리디
- 우종정
- 백준
- 정렬
- 답
- java
- Python
- 운영체제
- 연습문제
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |